Using a compressed diff instead of lines of code
Lines of code (LOC) has some known flaws, but one of its advantages is that it lets humans visualize it for a small enough number. For bigger numbers like 100,000 vs 200,000 lines of code it really doesn't help us humans picture it.
For big enough changes, you could switch to just compressing the diff and measuring that. That also nicely tracks what developers would have to actually download to get the new changes. It also helps with understanding the bandwidth requirements of contributing to a project.
Here is what it looks like for the Linux kernel since 4.1. (For Rc1s only - the other rcs are in the 30-100 KiB range)
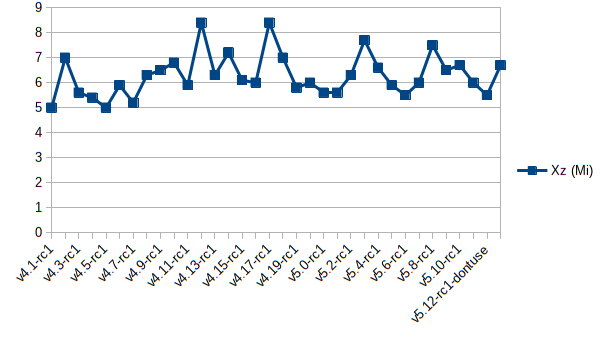
Here is a comparison of how far apart the LOC numbers are from the compressed diff numbers - the longer the line is the further apart they are. The numbers are normalized to 0-1. As you can see, they generally line up.
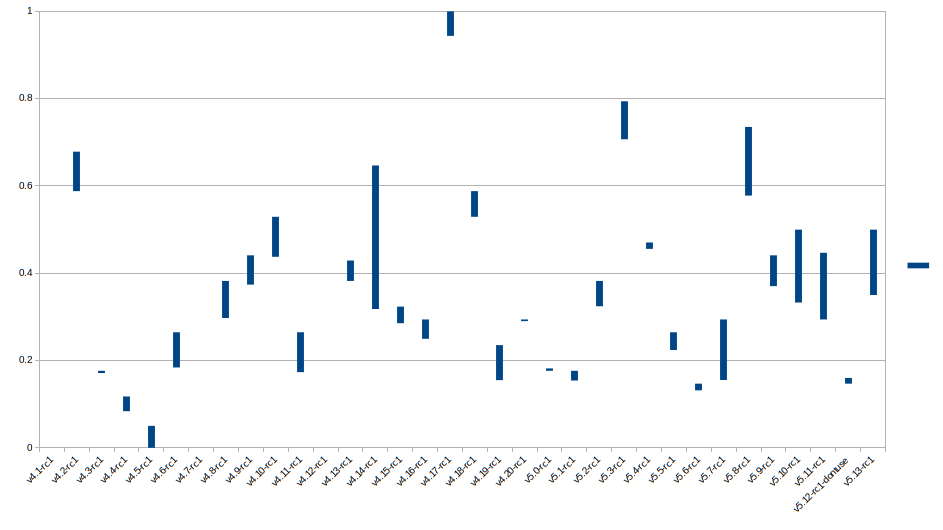
(You can get the raw spreadsheet here )
Let's get some numbers from another project - say systemd.
$ git tag --list --sort=creatordate | tail #Pick the last two major releases.. $ git diff v247 v248 | xz -c -q | wc -c | numfmt --to=iec-i --round=nearest 1.1MiB
Conclusion
This isn't ground breaking, but it may prove to be slightly more useful than using LOCs. At the very least as an alternative, it could help put less emphasis on LOCs.
Some interesting future things to look at:
- Better comparisons between software projects using different languages?
- Tracking other changes to software projects in a similar way (Wikis, MLs).
- Compare with other kinds of projects. For instance Wikipedia does track changes monthly by the GB.
Comments and Feedback
Feel free to make a PR to add comments!